Sticky Badness: Metastability and you
19 Mar 2023In the physical sciences, there’s a concept called metastability which is an apt metaphor for understanding certain kinds of software engineering failure modes. My grasp of this physics concept is entirely based on Wikipedia’s description, so take this with a grain of salt, but imagine you have a ball sitting in a well, like the red one labelled ‘1’ below:
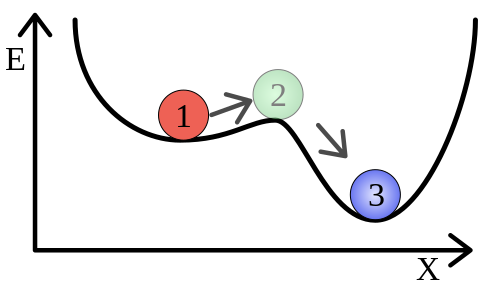
Undisturbed, it will sit happily. Nudge it a bit and it’ll roll right back into the bottom of the depression on the left and eventually come back to a rest. Nudge it enough, though, and it’ll hit position 2 and then tip down into the deeper well of position 3, from which it’ll be more difficult to dislodge.
Software systems sometimes exhibit behavior like this: small perturbations (a spike in load, an interruption in network availability, a slow disk access) might cause a temporary degradation of service, but generally will resolve without intervention. Sometimes, however, a critical threshold is crossed wherein a feedback loop takes over, holding the system in a bad state until a radical intervention (rebooting, load shedding, etc) is undertaken.
The paper Metastable Failures in Distributed Systems by Bronson, Aghayev, Charapko, and Zhu discusses these kinds of failures in more detail, and provides a succinct definition:
Metastable failures occur in open systems with an uncontrolled source of load where a trigger causes the system to enter a bad state that persists even when the trigger is removed.
The authors stress that it is the feedback loop (the depth of the second well in our ball analogy), rather than the trigger (the nudge) that should rightly be thought of as the ‘cause’ of a metastable failure:
It is common for an outage that involves a metastable failure to be initially blamed on the trigger, but the true root cause is the sustaining effect.
A case study
This failure mode might sound rare, but my team at work recently spent some time tracking down a metastable failure state in a very standard looking system: a pool of stateless HTTP servers, each with a database connection pool, which looked something like this:
This system was replacing an older one, but before the replacement we ran an extended load test by mirroring all production traffic from the old system to the new one (silently discarding the results from the new system). In so doing, we encountered a failure mode that only manifested occaisionally, but was catastrophic when it did. The symptoms:
- Near 100% CPU utilization on the target database
- Application latency pegged at our app-layer timeout (2 seconds)
- 100% error rate for the application (with all failures being timeouts)
- Observed across multiple application instances concurrently
- No obvious changes in inbound application throughput or access patterns
Once triggered, the application would remain in this bad state until it was stopped and restarted (scaled to zero and then back up to the target instance count).
Closer examination revealed that the application instances were cycling through database connections at a very high rate. In fact, each request was attempting to establish a new database connection, but timing out before it was able to finish doing so, leaving the connection pools effectively empty.
Reproducing the issue
A failure mode like this can be hard to believe until you’ve successfully triggered it on-demand. While investigating this failure, we relied on a slimmed down test case involving a single application instance and a local database. Running locally, the cost differential between establishing a new DB connection and issuing a query over an existing one was smaller (we did local testing without TLS on the database connection, and without utilizing a database proxy component that was present in production), so it took some finagling to get a suitable reproduction case.
In order to better simulate the cost of new connection establishment, we wrapped a rate limiter around DB connection creation, forcing new connection attempts to block once the threshold rate was exceeded. In reality, the database CPU effectively functioned as this rate limiter. A full TLS handshake takes an appreciable amount of CPU time. Add to that other database-specific CPU work needed to prepare a new connection for use, and you can begin to see how a small number of instances, each with a modest connection pool might saturate the CPU of a database with reconnection attempts.
Inducing the issue in production
Simultaneously, my team had been working on ways to induce the issue under production load levels. The initial idea was to consume all available database CPU resources for a brief period of time (long enough for us to trigger application timeouts and thus connection reestablishment). This proved to be more challenging than it might sound (unsurprisingly, most material you’ll find online about consuming database CPU resources is written with the premise that you want to use less not more of them).
The thing that did finally work to trigger this failure mode was to hold an ACCESS EXCLUSIVE lock against a table read by most application requests for a few seconds, like this:
BEGIN;
LOCK TABLE t IN ACCESS EXCLUSIVE MODE;
SELECT pg_sleep(5);
COMMIT;
Using this approach, we were able to reliably trigger the failure state, which was critical to building our confidence that we had actually addressed the issue once we implemented a mitigation strategy.
Mitigation
Metastable Failures in Distributed Systems discusses several strategies for dealing with metastable failure states. The one we employed on my team to address this particular problem was a simple circuit breaker around all database interactions.
Our circuit breaker works by keeping a running count of the number of consecutive query failures it has observed, and immediately aborting any database queries for a certain amount of time once a configurable number of failures has been observed. The amount of time queries are disabled for scales exponentially with the number of failures (up to a fixed upper bound), and any successful query resets the failure count back to zero.
The state diagram looks like this:
A circuit breaker breaks the feedback loop: requests that arrive during the period when the circuit breaker is open are immediately aborted, shedding load on the database. The consecutive failure counter ensures that we don’t needlessly open the circuit breaker unless we have strong evidence that the next query is likely to fail.
Results
Without the circuit breaker, we were able to repeatedly trigger a persistent failure state using the locking approach described above. Once the circuit breaker was implemented, the same reproduction steps yielded recovery within seconds after the release of the lock. We’ve not seen any organic recurrences of the issue since the addition of the circuit breaker either.
Simulation
We can better understand this failure mode using a simplified simulation. I created one using SimPy, a discrete event simulation framework for Python. (Discrete event simulation just means that instead of simulating every ‘tick’ of simulated time, the simulation jumps between discrete events, which may trigger or schedule other events.)
The simulation models a fixed number of application instances, each with a fixed-size database connection pool, all connecting to a single database instance. Requests are randomly distributed amongst instances, and each request involves executing a single database query. The database query consumes a small amount of database CPU time, and simulates network latency between the application and the database by holding the connection from the pool for some additional time.
Requests have a timeout, and if the timeout fires during the execution of the database query, the connection that was being used for that request is marked as dead, and will be refreshed on the next use. The refresh process incurs a higher database CPU cost.
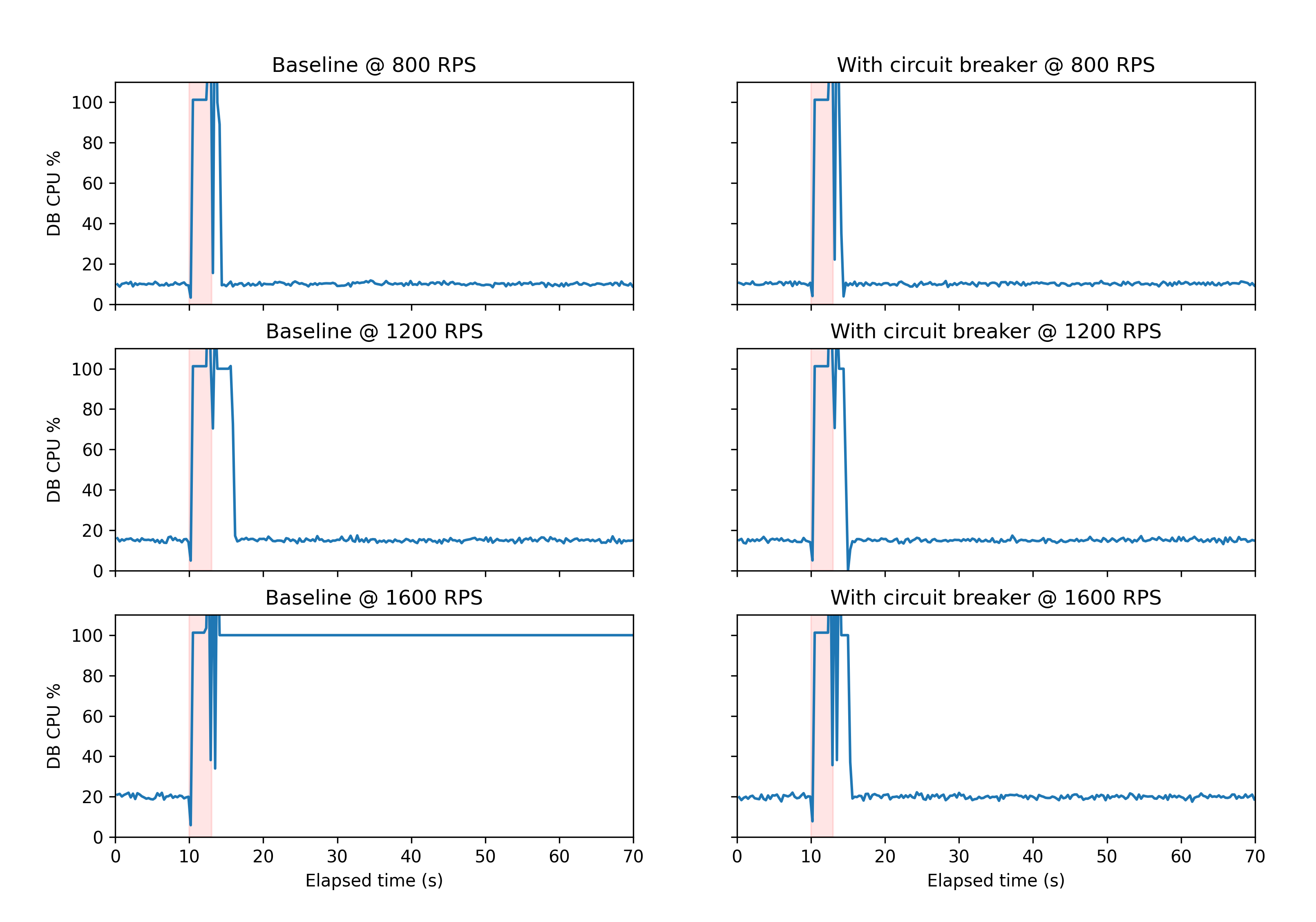
In order to simulate a trigger, the model holds all database CPU resources for a few seconds after an initial delay. A well-behaved system is expected to experience application timeouts during this period, since no other database queries get CPU time to execute. At lower throughput values, this is indeed what happens: the application sees a brief period of timeouts that is similar in duration to the triggering event itself. However, at higher throughputs, the application never recovers from its error state, as repeated timeouts lead to reconnection attempts, which in turn consume database CPU resources, and cause further timeouts.
The addition of a circuit breaker to the system allows for recovery from this state. In the charts below, you can see the results of simulating 70 seconds worth of time both without (left column) and with (right column) a circuit breaker.
The y-axis in each chart shows the database CPU utilization, and the x-axis shows time. The pink shading indicates the time during which the database CPU is artificially pinned at 100% usage by the simulation in order to induce the failure mode.
You might have a metastable system!
If your system seems to ‘enter a bad state’ under load from which it can’t recover without operator intervention, you too might have a metastable system. They’re not as rare as you might think! Check out the section 3 (‘Approaches to Handling Metastability’) of the paper I linked to previously to get some ideas as to how you might break the feedback loop in your system.
Acknowledgements
Many thanks to my friend Bill Dirks, who was a sounding board and consistent source of ideas and encouragement during the process of tracking this issue down!